


- Co to jest pozycjonowanie stron internetowych i SEO?
- Na czym polega pozycjonowanie?
- Czynniki on-Site off-Site
- SEO a Google Ads – różnica
- Jak działa wyszukiwarka Google?
- Algorytmy Google
- Geolokalizacja wyników wyszukiwania
- Czym są słowa kluczowe?
- Jak dobierać słowa kluczowe?
- Kanibalizacja słów kluczowych w pozycjonowaniu
- Co to takiego jest kanibalizacja fraz?
- Rodzaje słów kluczowych
- Brandowe słowa kluczowe
- Słowa kluczowe ogólne
- Słowa kluczowe mid-tail / long-tail
- Treści na stronie internetowej
- Duplikacja wewnętrzna
- Duplikacja zewnętrzna
- Rodzaje linków
- Jak pozyskiwać linki zewnętrzne?
- Linkowanie wewnętrzne
- Szybkość ładowania strony, a pozycjonowanie
- Optymalizacja techniczna strony w SEO
- Dostosowanie strony do urządzeń mobilnych
- Jak dostosować stronę do urządzeń mobilnych?
- Czy UX wpływa na pozycjonowanie?
- Pozycjonowanie strony a konwersja
- Czym jest pozycjonowanie lokalne?
- Wizytówka w Google Moja Firma
- Lokalne słowa kluczowe
- Spójność danych teleadresowych
- Opinie o firmie
- Jak działają agencje SEO?
- Etapy pozycjonowania strony
- Ile trzeba czekać na efekty pozycjonowania?
- Ile kosztuje pozycjonowanie?
- Współpraca z agencją SEO czy samodzielne pozycjonowanie?
- Gdzie szukać pomocy w pozycjonowaniu stron www?
- Mity spotykane na temat SEO
- Najczęściej zadawane pytania - FAQ
Co to jest pozycjonowanie stron internetowych i SEO?
Pozycjonowanie strony to obowiązek każdej Firmy, która chce zaistnieć w internecie. W końcu należy być tam gdzie są Twoi klienci a ilość internautów w Polsce każdego dnia rośnie. Zanim potencjalni klienci trafią na Twoją stronę, najprawdopodobniej skorzystają z wyszukiwarki Google, która ma 97,87% udziałów w rynku według statcounter.
Udział Google w rynku według statcounter.com
| Search Engine | Market Share |
|---|---|
| 97.87% | |
| Bing | 1.19% |
| Yahoo! | 0.52% |
| MSN | 0.11% |
| DuckDuckGo | 0.11% |
| YANDEX RU | 0.05% |
Oznacza to, że musisz zadbać o to by Twoja strona znalazła się odpowiednio wysoko w wynikach wyszukiwania, jeśli chcesz pozyskiwać nowych klientów. Najlepiej zacząć walkę o klientów z sieci poprzez pozycjonowanie strony w Google.
Na czym polega pozycjonowanie?
Pozycjonowanie w wyszukiwarkach internetowych są to zabiegi i działania skierowane na zwiększenie widoczności danej strony w wynikach wyszukiwania (tzw. SERP Search Engine Results Page.W jego zakres wchodzą działania on-Site (na samej stronie) oraz off-Site (na innych witrynach).
Część działań jest jawnie dozwolona (White Hat SEO), a część z nich nie jest zgodna z wytycznymi wyszukiwarek (Black Hat SEO).
W ramach pozycjonowania można spotkać się też z terminem SEO (search engine optimization), który zwyczajowo stosowany jest zamiennie z pozycjonowaniem, co w języku polskim nie jest do końca poprawne
.
Czynniki on-Site off-Site
Czynniki on-Site |
Czynniki off-Site |
|---|---|
| W ramach działań on-site SEO wchodzą aspekty związane głównie z techniczną optymalizacją witryny pod wyszukiwarki oraz dodawaniem unikalnych treści na stronę. Do najważniejszych z nich można zaliczyć między innymi: | W ramach działań on-site SEO wchodzą aspekty związane głównie z techniczną optymalizacją witryny pod wyszukiwarki oraz dodawaniem unikalnych treści na stronę. Do najważniejszych z nich można zaliczyć między innymi: |
|
|
White-hat SEO vs black-hat SEO
Pozycjonowanie polega na poprawianiu widoczności witryny w wyszukiwarkach. Można to robić w dwojaki sposób. Zgodnie z ogólnymi normami i wytycznymi od Google (White Hat) lub w sposób manipulujący wyszukiwarką z pomocą niedozwolonych zabiegów (Black Hat). O ile działania niezgodne z zaleceniami Google mogą przynieść krótkotrwałe sukcesy to na dłuższą metę mogę narazić stronę na karę od Google i obniżenie pozycji.

Co więcej może też na tym stracić cała domena, co spowoduje zmarnowanie wysiłków ostatnich lat włożonych w pozycjonowanie. Dlatego zaleca się stosowanie ogólnie przyjętych zasad i unikanie sztucznego manipulowania wynikami. Ponieważ wiele aspektów związanych z pozycjonowaniem balansuje na granicy White i Black Hat nie zaleca się prowadzenie tego typu działań na własną rękę tylko przy wsparciu specjalistów.
SEO a Google Ads – różnica
Po wpisaniu dowolnego zapytania do wyszukiwarki Google można otrzymać dwa podstawowe rodzaje wyników. Pierwsze z nich to wyniki PPC (Pay per Click) z systemu Google Ads nazywane zwyczajowo wynikami płatnymi, gdyż zależą od stawek za kliknięcie jakie może właściciel strony zaoferować. Drugie, wyświetlane poniżej to wyniki organiczne, których kolejność zależy od dopasowania do zapytania w ocenie wyszukiwarki. Podstawową różnicą między nimi jest czas działania.
Wyniki płatne (z Google Ads) dają efekt prawie natychmiast po zasileniu konta i skonfigurowaniu kampanii. Natomiast na wysokie pozycje w ramach wyników organicznych, na które wpływa pozycjonowanie potrzeba trochę czasu. Nie sposób oceniać, które z powyższych działań jest lepsze, gdyż warto pojawiać się zarówno w jednych jak i drugich.
Warto przy tym pamiętać, że w ramach pozycjonowania i poprawiania wyników organicznych osiągane efekty są długofalowe i można działać na dużo większą skalę słów kluczowych. W przypadku Google Ads i wyników płatnych jest to też możliwe, jednak wymaga dużo większego wkładu finansowego zarówno w samą kampanię jak i jej obsługę. W większości firmy działające w sieci traktują pozycjonowanie jako długofalową inwestycję a wyniki płatne jako środek doraźny (też prowadzony przez cały rok, ale z większymi budżetami w sezonie).
Jak działa wyszukiwarka Google?
W jaki sposób działa Google wyświetlając wyniki dla zapytania? W dużym skrócie Google znajduje, indeksuje, ocenia i wyświetla strony internetowe.
Google zbiera informacje o stronach internetowych z innych istniejących już stron oraz z informacji dostarczanych bezpośrednio przez użytkowników (poprzez Google Maps, Google Search Console, Google Moja firma). To działanie jest prowadzone bez przerwy od samego początku działania wyszukiwarki.
Następnie każdą znalezioną stronę spełniającą podstawowe wymogi Google stara się dopasować tematycznie i zapisać informacje o niej w wewnętrznym indeksie. Proces ten nazywany jest indeksowaniem i jest konieczny do tego by strona w ogóle się pojawiła w wynikach.
Na sam koniec Google wyświetla wyniki zależne od zapytania. W tym celu próbuje znaleźć jak najlepszą odpowiedź przeszukując zbiór stron, które posiada w indeksie. Ilość czynników wpływająca na kolejność i ocenę przydatności jest bardzo duża i większość z nich nie jest jawna. Co więcej tego samego dnia dla takiego samego zapytania wyniki mogą się od siebie różnić, choćby dlatego, że użytkownik piszący zapytanie znajdował się w innym miejscu (geolokalizacja).
Algorytmy Google
Na kolejność wyników w wyszukiwarce ma wpływ bardzo wiele czynników. Co jakiś czas zasady na bazie, których są one segregowane ulegają zmianie. Cały system opracowany przez Google opiera się na wielu algorytmach oceniających strony względem określonych kryteriów, takich jak na przykład profil linków przychodzących, linki wewnętrzne, jakość prezentowanej treści, szybkość wczytywania strony itd.
Google nie przedstawia wszystkich aspektów, które bierze pod uwagę w sposób jawny. Jednak o tym, że wprowadza zmiany raz na jakiś czas informuje opinię publiczną. Tak się stało między innymi przy wprowadzaniu takich aktualizacji jak Google Pingwin, czy Google Panda, które wywróciły wyniki do góry nogami (poprzez radykalną zmianę zasad segregowania wyników).
Chcąc pozyskiwać ruch organiczny bezpośrednio z wyszukiwarki należy na bieżąco obserwować jakie zmiany są wprowadzane i jakie czynniki wpływają na pozycję. Jest to jedno z głównych zadań pozycjonerów czuwających nad widocznością stron internetowych.

Geolokalizacja wyników wyszukiwania
Niektóre zapytania kierowane do wyszukiwarki mają charakter stricte lokalny. Czasem w tym celu użytkownicy dopisują do szukanej frazy nazwę miasta, w którym się znajdują lub gdzie chcą dane dobro lub usługę odnaleźć (na przykład: fryzjer męski poznań, buty trekingowe poznań).
Jednak bardzo często w celu uzyskania ogólnych informacji na temat produktu nie podaje się do wyszukiwarki miasta, które nas interesuje. W takich przypadkach Google mimo to będzie starał się w miarę możliwości podać wyniki dopasowane do naszego położenia (zwłaszcza dla działalności stricte lokalnych).
Oznacza to, że na przykład dla ogólnego zapytania hale stalowe, zupełnie inne wyniki otrzyma osoba z Gdańska a inne z Wrocławia. Dlatego warto zadbać o odpowiednie dopasowanie witryny do lokalnych wyników zarówno jak się prowadzi działalność w okrojonym obszarze jak i w całej Polsce.
Czym są słowa kluczowe?
Kluczem pozycjonowania stron są słowa kluczowe, nazywane też frazami. Nazywa się tak słowa (lub ich zbiory), które wpisują użytkownicy do wyszukiwarki. To poprzez konkretne frazy potencjalni klienci trafiają na Twoją stronę internetową prosto z Google, dlatego należy zwrócić na nie szczególną uwagę.
Bez odpowiednio dobranych słów kluczowych i odpowiedniej ich ilości (jak największej), trudno rozpocząć działania związane z SEO czy pozycjonowaniem.
Jak dobierać słowa kluczowe?
Każdy z nas inaczej wyraża swoje myśli i potrzeby zależnie od okoliczności i osobowości. Ma to bezpośrednie przełożenie na korzystanie z wyszukiwarki. Inaczej wyglądają zapytania na początku ścieżki zakupowej niż w jej środku czy też końcu.
Przykładowo chcąc kupić nóż do survivalu lub pobytu na łonie przyrody najprawdopodobniej użyjemy frazy:
| „NÓŻ SURVIVALOWY” | „NÓŻ” | „NÓŻ DO DREWNA” |
|---|
Zgłębiając temat bardziej jeszcze przed podjęciem ostatecznej decyzji kolejne zapytania będą bardziej sprecyzowane jak na przykład:
| „NÓŻ Z GŁOWNIĄ STAŁĄ” | „NÓŻ SPRĘŻYNOWY” | „NOŻ OPINEL” | „NÓŻ MORA” (RENOMOWANA SZWEDZKA MARKA) |
|---|
Na końcowym etapie, gdy już będziemy przekonani o tym czego szukamy zapytania będą jeszcze bardziej sprecyzowane, czasem oparte nawet o konkretny model: „nóż mora garberg”, „nóż opinel inox”. Możliwości doboru fraz jest mnóstwo. W większości przypadków im więcej tym lepiej i z czasem należy poszerzać zakres fraz na jakie się stawia. Zwłaszcza na frazy tzw. długiego ogona (bardzo szczegółowe), gdyż mają one dużo większy potencjał sprzedażowy.
Jednym z kluczowych zadań pozycjonowania jest dobór fraz i ocena szans na osiągnięcie dobrych pozycji dla konkretnych zapytań w zależności od wyszukiwalności fraz i ich potencjału sprzedażowego.
Kanibalizacja słów kluczowych w pozycjonowaniu
Mogłoby się wydawać, że należy dobierać jak najwięcej fraz kluczowych na jakich nam zależy i tworzyć dla nich nowe podstrony, aby wspierać pozycjonowanie z założeniem, że im więcej tym lepiej. Nie jest to do końca prawdą, gdyż trzeba zwrócić uwagę na kanibalizację słów kluczowych
.
Co to takiego jest kanibalizacja fraz?
To sytuacja w której dla danego zapytania rankuje w wyszukiwarce kilka różnych podstron danej witryny. Ponieważ Google limituje ilość wyników z danej domeny do 2 maksymalnie (poza skrajnymi przypadkami), gdy więcej podstron jest zopotymalizowanych pod to samo słowo kluczowe, to mogą one między sobą konkurować i nie zawsze będzie się wyświetlała podstrona, która powinna mieć najlepszą pozycję.
Wykrycie tego zjawiska samodzielnie bez specjalistycznych narzędzi może być trudne, jednak dla specjalistów SEO korzystających z zasobów agencyjnych jest to chleb powszedni.
Rodzaje słów kluczowych
Frazy kluczowe wpisywane do wyszukiwarki przyjmują wiele form, zależnie od intencji użytkownika i tego czego w danym momencie szuka. Mimo, że każdy wyraża swoje potrzeby w inny sposób to słowa kluczowe za pomocą, których użytkownicy poszukują informacji można podzielić na kilka podstawowych grup.
Brandowe słowa kluczowe
Słowa kluczowe zawierające brand są stosowane wtedy, gdy potencjalny klient miał już kontakt z daną marką lub szuka towaru od konkretnego producenta. Przykładem takiej frazy mogą być buty męskie lasocki. Osoba wpisująca taką frazę już wcześniej zapoznała się z konkretną marką i szuka konkretnego modelu, który ją interesuje lub ma zufanie do wyrobów tej firmy. Warto zwrócić uwagę, że w tym przypadku nie jest to brand własny (konkretnego sklepu) a towaru, który jest dostarczany.
Słowa kluczowe ogólne
Na początku ścieżki zakupowej użytkownik często nie wie czego dokładnie szuka. Przykładowo, mężczyzna odświeżając swoją garderobę na chłodne dni, będzie chciał znaleźć po prostu: „buty męskie” (fraza ogólna).
W zależności od wyników może zawężać swoje wyszukiwanie do frazy: „buty zimowe męskie”.
Po dalszym zapoznaniu się z tematyką obuwniczą może podjąć decyzję, że potrzebuje: „skórzane buty zimowe męskie” i tak dalej.
Naturalnym jest, że każde kolejne wyszukiwanie będzie coraz bardziej dokładne a ścieżka zakupowa będzie przechodzić zazwyczaj od ogółu do szczegółu.
Słowa kluczowe mid-tail / long-tail
Bardzo mało osób kończy swój proces decyzyjny po znalezieniu informacji z ogólnych fraz kluczowych. To zachowanie w sieci ma także odzwierciedlenie w świecie rzeczywistym. Wchodząc do sklepu w celu nabycia jakiegokolwiek produktu rzadko kiedy wybieramy pierwszy, który stoi na tematycznej półce lub zaoferowany przez specjalistę / konsultanta. Zazwyczaj zadajemy pytania doprecyzowujące.
Kontynuując przykład z butami cała ścieżka mogłaby się rozpocząć od „butów męskich” przez „buty zimowe męskie” a po sugestii sprzedawcy dojdziemy do wniosku, że dobrym wyborem będą te wykonane ze skóry. W zależności od doświadczeń z różnymi markami wybór może paść na buty od Lasockiego. Jednak czy już wtedy zdecydujemy się na zakup pierwszej lepszej pary „butów skórzanych męskich zimowych Lasocki”? Raczej niekoniecznie, przecież but musi na nas pasować i być w odpowiednim kolorze pasującym do reszty ubioru. Wtedy użyjemy frazy z tak zwanego długiego ogona o dużym stopniu sprecyzowania jak na przykład: „buty skórzane zimowe męskie lasocki czarne 44”.
Wiedza o tym jak funkcjonują ścieżki zakupowe jest bardzo istotna w procesie pozycjonowania i warto zadbać o szeroki wachlarz słów kluczowych aby pozyskiwać klientów na każdym etapie lejka sprzedażowego.
Treści na stronie internetowej
Google jest przede wszystkim wyszukiwarką tekstową. Dlatego dystrybucja treści w witrynie jest bardzo kluczową sprawą w procesie pozycjonowania i jednym z ważniejszych aspektów w ramach działań on-site (i nie tylko). Im lepsza, precyzyjniejsza i bardziej dopasowana do użytkownika treść na stronie internetowej tym lepiej jest ona oceniana, a co za tym idzie może osiągać dużo lepsze pozycje na szeroki wachlarz słów kluczowych.
Dotyczy to prawie wszystkich możliwych podstron od strony głównej przez strony kategorii, podstrony usług i produktów aż po specjalne landingi i wpisy blogowe. W kontekście walki o wysokie pozycje treść ma znaczenie i powiedzenie Content is King ma realne przełożenie na pozyskiwanie odbiorców o ile treść jest wartościowa.
Duplikacja wewnętrzna
Bardzo często na stronach internetowych poszczególne podstrony przedstawiają prawie tą samą lub bardzo podobną treść lub jej fragmenty. Na przykład fragmenty regulaminów, informacje o RODO, sposobach wysyłki i tym podobne. Często też poszczególne produkty różnią się między sobą tylko drobnymi szczegółami jak na przykład kolor czy rozmiar, co powoduje że ich opisy są prawie takie same z wyjątkiem kilku słów.
Wydawać by się to mogło naturalne, jednak Google i jego algorytmy nie zawsze są w stanie to zidentyfikować i mogą to uznać za niepotrzebne powielenia. Chcąc tego uniknąć należy przygotować unikalne treści dla poszczególnych podstron lub niektóre z nich połączyć albo dać znać robotom wyszukiwarki, że dane fragmenty są częściowym powieleniem (na przykład na stronach kategorii z włączonymi filtrami wyszukiwania). Dobór właściwego rozwiązania w zakresie duplikacji wewnętrznej zależy od struktury strony oraz użytych technologii i stopnia podobieństwa opisów a decyzja jak z tym walczyć leży w rękach pozycjonera.
Duplikacja zewnętrzna
Jeszcze większym zagrożeniem dla witryny w kontekście podobieństwa tekstów jest duplikacja zewnętrzna treści. W przypadku idealnym prezentowany tekst powinien być w 100% unikalny w skali całego internetu i w ramach pozycjonowania dba się o to by wszelkie odstępstwa od tej zasady eliminować.
W przypadku małych witryn lub tych z mniejszym nierotującym asortymentem nie jest to aż tak znaczącym problemem, gdyż „wystarczy” przeredagować powielające się treści zaciągnięte między innymi ze stron producentów (w przypadku opisów produktowych). Jednak przy większej skali gdy produktów jest znacznie więcej i dość często się zmieniają należy podejmować dużo mocniejsze i bardziej radykalne działania mające na celu uniknięcie takiej duplikacji oraz wzmocnienie innych aspektów SEO.Teoretycznie można i dobrze by było posiadać indywidualne opisy wszystkich podstron i produktów, ale przeredagowanie 100.000 opisów może okazać się nierentowne i lepiej jest powierzyć sprawę specjalistom, którzy zadbają by strona nie była negatywnie rozpatrywana przez wyszukiwarkę, chociażby przez odpowiednie przekierowania lub atrybuty rel canonical.
Rodzaje linków
Linki, czyli inaczej hiperłącza to sposób na odwołanie się do innych witryn lub podstron danej strony internetowej. Składają się one z dwóch podstawowych elementów: części widocznej / klikalnej oraz adresu, do którego po kliknięciu odsyłają. W ramach działań związanych z pozycjonowaniem ważne jest dywersyfikowanie profilu linkowego poprzez stosowanie różnego rodzaju linków.
|
Rodzaje linków |
Opis linków |
|---|---|
Linki brandowe |
Linki brandowe, czyli posiadające anchor (klikalną część linka) z nazwą firmy lub brandu opcjonalnie nazwą domeny. Z ich pomocą buduje się rozpoznawalność samej strony i są stosunkowo bezpieczne w stosowaniu przy działaniach link-buildingowych. Ogólnie takie linki wyglądają w następujący sposób:
|
Exact Match |
Linki mogą posiadać w swojej klikalnej części frazę, którą użytkownik mógłby wpisać do wyszukiwarki. Tego typu odnośniki mają dużo większą moc niż pozostałe typy linków. Należy jednak uważać z ich stosowaniem, gdyż jak będzie ich zbyt dużo to strona może dostać stosowną karę, przez co przestanie pojawiać się na wysokich pozycjach w wyszukiwarce.
Co więcej konkurenci stosujący nieuczciwe praktyki mogą w ten sposób linkować Twoją stronę na frazy niezwiązane z Twoją działalnością by pogorszyć jej pozycję. Proces ten jest nazywany depozycjonowaniem stron. |
Linki graficzne |
Linki graficzne w odróżnieniu od tekstowych charakteryzują się tym, że klikalny nie jest tekst tylko grafika / zdjęcie. Często można je spotkać w działaniach reklamowych lub sidebarach (w postaci banerów lub sliderów). Linki graficzne w kodzie html implementuje się następująco: |
Linki URL |
Linki URL to takie, które w swojej klikalnej części posiadają pełny lub częściowy adres do podstrony, do której kierują. Przykład takiego odnośnika może wyglądać następująco:
Gdzie element klikalny jest taki sam jak adres zasobu. Jest to najpopularniejszy rodzaj linków w Internecie, gdyż zazwyczaj wysyłając komuś link lub komentując w mediach społecznościowych czy innych miejscach nie opisuje się linków w żaden dodatkowy sposób. |
Linki zewnętrzne |
Pozyskiwanie odnośników spoza własnej strony to jedno z najważniejszych działań związanych z pozcyjonowaniem w zakresie off-site. Opiera się ono o prostą analogię ze świata, że im więcej osób poleca daną rzecz to jest ona bardziej wartościowa. Tak też jest w ramach SEO. Co więcej już od dłuższego czasu coraz większe znaczenie ma jakość tych odnośników a nie ich ilość. W końcu zdanie profesora w danej dziedzinie jest więcej warte niż opinia dwóch przypadkowo napotkanych osób.
Kwintesencją pozyskiwania linków zewnętrznych w ramach działań off-site jest znalezienie złotego środka między ilością a jakością źródeł i dopasowanie strategii do istniejącego już profilu linkowego. |
Jak pozyskiwać linki zewnętrzne?
Zdobywać nowe linki można próbować praktycznie z każdego miejsca w internecie. Mogą to być linki z for internetowych, stron branżowych, komentarzy z blogów, stron producentów, instytucji charytatywnych czy artykułów sponsorowanych na wszelkiego rodzaju portalach. Dodatkowo większość agencji SEO posiada własne zaplecza stron, z których może pozyskiwać linki zarówno dla siebie jak i swoich klientów. Dzięki temu mają one dużo większą kontrolę nad tym jak linkowana jest strona i w razie potrzeby mogą zmienić strategię. Pozyskiwanie linków do witryny to proces długofalowy i czasochłonny, w którym duża część czasu jest przeznaczona na analizy i weryfikację źródeł.

Linkowanie wewnętrzne
Nie tylko linki zewnętrzne mają znaczenie w pozycjonowaniu. Bardzo istotnym aspektem działań on-site jest tworzenie odpowiednich linków wewnętrznych pozwalających łączyć poszczególne podstrony serwisu wzmacniając je w ten sposób. Im więcej tematycznych linków do danej podstrony w obrębie serwisu tym większa „moc” jest jej przekazywana.
Z pomocą linkowania wewnętrznego można bardzo dużo zdziałać, gdyż Google bierze je pod uwagę. Wynika to z prostej analogii ze świata rzeczywistego. Jeśli w danej organizacji konkretną osobę / specjalistę wiele osób uważa za dobrą w swoim fachu i ją poleca to coś musi być na rzeczy. W kontekście stron internetowych jest podobnie. Dzięki odpowiedniemu linkowaniu wewnątrz witryny można wspomóc poszczególne podstrony by lepiej rankowały na określone słowa kluczowe.
Szybkość ładowania strony, a pozycjonowanie
Czas to pieniądz, a informacja ma wartość jeśli możemy ją szybko pozyskać w określonym momencie, bo nikt nie lubi czekać. Google też ma tego świadomość, dlatego jednym z czynników jakie bierze pod uwagę w ocenie witryny jest szybkość wczytywania strony. W celu diagnozowania stanu strony pod kątem jej ładowania korzysta się z takich narzędzi jak:
Zadaniem pozycjonerów jest diagnozowanie i w miarę możliwości eliminowanie elementów opóźniających ładowanie strony, w tym części ATF (Above the Fold) będącej pierwszym widokiem, który użytkownik zobaczy po wejściu na stronę. W skrócie im szybciej, tym lepiej!
Optymalizacja techniczna strony w SEO
Poprawianie strony od strony technicznej tak by poprawić SEO witryny jest żmudnym procesem będącym podwaliną działań on-site. Oprócz poprawiania szybkości wczytywania strony poprawia się jej strukturę w tym semantykę kodu HTML, tytuły stron oraz nagłówki, dodaje dane strukturalne i wiele więcej.
W ramach optymalizacji przeprowadza się też analizę indeksacji witryny oraz jej dostępność dla robotów poniekąd śledząc gdzie i kiedy roboty Google odwiedzają i indeksują poszczególne podstrony. Aby to było możliwe strona jest wielokrotnie skanowana specjalnymi narzędziami (zwanymi crawlerami), by móc sprawdzić każdą podstronę z osobna pod kątem istotnych parametrów.
Często w wyniku takich analiz wykrywa się nieaktywne lub niedziałające linki, które należy usunąć lub przekierować (na przykład za pomocą przekierowania 301). Zazwyczaj sprawdza się też jak strony są między sobą połączone i na tej podstawie planuje się linkowanie wewnętrzne w witrynie.
Optymalizacja techniczna witryny zwłaszcza w żyjących i aktywnych serwisach nie ma końca. Co dzień pojawiają się kolejne rzeczy do zmiany, dochodzą nowe podstrony a Google też zmienia niektóre kryteria oceny stron co nie ułatwia sprawy. Ma tu zastosowanie jedno z Praw Weilera „Jeżeli program jest użyteczny, to będzie musiał być zmieniany.”, które przekłada się także na strony i serwisy internetowe.
Dostosowanie strony do urządzeń mobilnych
O powszechności użycia urządzeń mobilnych w celu wyszukiwania informacji chyba nie trzeba nikogo przekonywać. O ile kilka lat temu mogło być to opcjonalne to obecnie jest koniecznością. Zauważyła to też firma Google, która oceniając stronę sprawdza także jej dostępność dla urządzeń mobilnych. Co więcej powstały nawet specjalne roboty i algorytmy, które to sprawdzają i indeksują. Zauważyć to można także w wynikach. Będąc w tej samej lokalizacji kolejność wyników na urządzaniu mobilnym jak i stacjonarnym może się od siebie różnić!

Jak dostosować stronę do urządzeń mobilnych?
W większości przypadków należy zadbać o responsywność strony, czyli o to by dopasowywała swoją treść do szerokości urządzenia na którym jest otwierana. Dodatkowo warto zwrócić uwagę na:
Z zasady nie powinno się też prezentować innych treści użytkownikom na urządzeniach mobilnych niż tym na desktopach.
W całym tym procesie tworzenia wytycznych mających na celu dostosowywanie strony do urządzeń mobilnych pod kątem SEO pomaga GSC (Google Search Console). Z jego pomocą można monitorować podstawowe elementy mające wpływ na ocenę w oczach Google. Pozostałe aspekty leżą już w gestii i doświadczeniu pozycjonera.
Czy UX wpływa na pozycjonowanie?
Oficjalną misją Google jest „uporządkowanie światowych zasobów informacji, tak by były powszechnie dostępne i użyteczne”. Potwierdza to też prowadzona przez Google retoryka dotycząca poprawiania pozycji stron w wyszukiwarce, że należy się skupić na tym, by strony były przyjazne dla użytkownika. Dlatego też coraz częściej w kontekście samego pozycjonowania zwraca się uwagę na UX serwisów internetowych i obie dziedziny coraz bardziej się łączą.
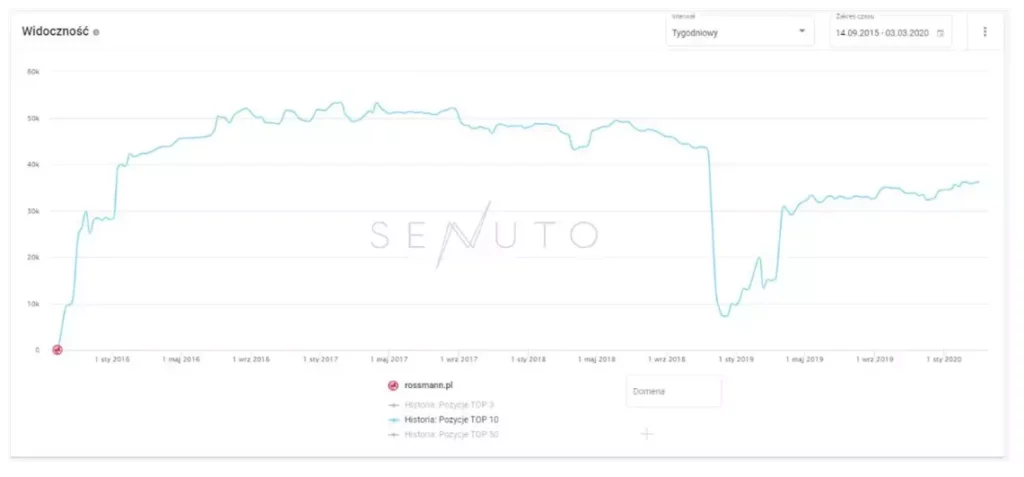
Niemniej należy pamiętać o tym, że UX wdraża się głównie dla użytkownika, tak aby jemu – Twojemu klientowi było wygodniej. Nie zawsze to idzie w zgodzie z tym co widzi Google a właściwie roboty indeksujące. Należy mieć na uwadze, że poprawiając użyteczność serwisu, należy zwracać uwagę jak widzą ją także roboty. O ile duża część zmian typowo UX-owych może wspomóc pozycjonowanie to powinny być one wykonane pod nadzorem specjalisty ds. pozycjonowania, aby widoczność serwisu nie spadła. Inaczej może taka zmiana być fatalna w skutkach.
Przykład spadku widoczności witryny po wdrożeniu aspektów UX z pominięciem SEO
Pozycjonowanie strony a konwersja
Konwersja w ramach działań marketingowych jest kluczowym aspektem. W końcu wokół niej wszystko się kręci i Tobie z pewnością też zależy aby użytkownicy wykonywali określone cele (jak na przykład zakup produktu).
Należy jednak pamiętać, że nie takie jest bezpośrednie założenie pozycjonowania. Jego zadaniem jest zwiększenie widoczności w wyszukiwarkach, czyli żeby Twoja witryna pojawiała się na wyższych pozycjach na określone zapytania oraz ilość zapytań, na które jest widoczna też wzrastała.
Zazwyczaj owocuje to zwiększeniem ruchu na stronie (więcej kliknięć z wyszukiwarki – ruch organiczny), jednak nie zawsze i nie oznacza to, że większy odsetek osób będzie nabywał produkty, tylko więcej osób, będzie mogło się zapoznać z Twoją ofertą.
Dojrzałe witryny, które już mają spory ruch organiczny oprócz pozycjonowania dbają o to by zwiększyć klikalność z wyszukiwarki (nie tylko pozycje mają znaczenie) oraz stosują się do zaleceń specjalistów UX.
Nie każdy prowadzi działalność na terenie całego kraju. Niektóre rodzaje działalności charakteryzują się stricte lokalnym zasięgiem, jak na przykład fryzjer czy mechanik. Przecież będąc w Rzeszowie nie potrzebuję informacji o mechanikach w Poznaniu. Google też o tym wie i geolokalizuje poszczególne zapytania. Oznacza to, że dla niektórych fraz Google wyświetli mapkę z najbliższymi firmami świadczącymi daną usługę, a wyniki w zależności od lokalizacji geograficznej pytającego będą się między sobą różnić. Wynika to z coraz mocniejszej personalizacji i regionalizacji wyników przez Google.
Takimi przypadkami zajmuje się pozycjonowanie lokalne, którego celem jest zwiększanie widoczności strony www w mapach Google oraz dla zapytań związanych z lokalizacją użytkownika.
Wizytówka w Google Moja Firma
Google jest realnym monopolistą jak chodzi o wyszukiwarki internetowe. Nic więc dziwnego, że w pierwszej kolejności bierze pod uwagę własne produkty i informacje w nich zawarte (w tym linki). Jednym z nich jest Google Moja Firma (GMF) – miejsce, w którym można opisać swoją działalność oraz umieścić dane o swojej działalności wraz z linkiem do strony. GMF ma szczególne znaczenie w pozycjonowaniu lokalnym, gdyż pomaga robotom w określeniu lokalizacji danej działalności dzięki czemu trafiasz do bardziej sprecyzowanej grupy odbiorców.
Usługa Google Moja Firma jest darmowa, ale jej konfiguracja i zarządzanie bywa czasochłonne. Dlatego bardzo często w ramach pozycjonowania firmy zajmują się przynajmniej częściowo taką wizytówką, aby poprawić pozycje strony internetowej.
Lokalne słowa kluczowe
Mimo coraz dokładniejszego dopasowania wyników do lokalizacji, bardzo wiele osób szuka usług w „stary sposób” podając miasto, dla którego wyniki chcą uzyskać. Na przykład mechanik samochodowy poznań albo fryzjer Gdańsk. Między innymi warto skupić się na tego typu słowach kluczowych aby nie utracić potencjalnego ruchu i klientów, którzy mogą skorzystać z Twojej oferty.
Warto wiedzieć, że nawet prowadząc działalność ogólnopolską frazy lokalne są godne uwagi. Wynika to z faktu, że klienci często chcą znaleźć wykonawcę, który jest pod ręką. Dodatkowo prowadząc działania SEO na konkretne lokalizacje można osiągnąć lepsze wyniki niż dla frazy ogólnej. W tym celu specjaliści SEO często tworzą landingi na poszczególne miasta (najczęściej wojewódzkie) i odpowiednio je łączą i linkują między sobą
.
Spójność danych teleadresowych
Chcąc zweryfikować daną firmę lub kontrahenta warto poznać jego przynajmniej podstawowe dane. Jeśli informacje o nim z kilku miejsc są spójne to można przypuszczać, że jest w jakimś stopniu wiarygodny. Natomiast jeśli informacje z różnych źródeł sobie przeczą lub są mylące to daje to do myślenia…
Tak samo działają algorytmy Google i to nie tylko w kontekście fraz i biznesów lokalnych. Im więcej spójnych wzmianek czy opisów firmy tym lepiej. W jaki sposób jest to weryfikowane? Przede wszystkim przez tzw. NAP (Name Adress Phone) czyli Nazwa, Adres i Telefon / Mail. Tworząc wizytówki firmy czy podpisując się na jakichkolwiek stronach zwłaszcza jeśli umieszcza się też link do własnej witryny należy zachować spójność tych danych. Najlepiej jak są one też spójne z GMF (Google Moja Firma).

Opinie o firmie
Nieważne jak mówią, ważne że o nas mówią – tak brzmi stare porzekadło. O ile jest w nim ziarno prawdy to dużo lepiej mieć pozytywne opinie o swojej działalności niż te negatywne. Ma to jeszcze większe znaczenie, gdy wraz z taką opinią idzie odnośnik do Twojej strony internetowej przez co nie tylko użytkownicy ale też wyszukiwarka możne negatywnie rozpatrywać witrynę.
Chcąc dbać o prawidłowe pozycjonowanie należy skupić się nie tylko na swojej stronie, jej treściach czy też linkach, ale na tym co mówią użytkownicy. W pierwszej kolejności warto się zastanowić skąd takie opinie się pojawiają (czy są realne czy działaniem konkurencji), czy można coś poprawić. Następnie zareagować na taką wzmiankę i opinię, co zaleca sam Google zwłaszcza w opiniach pod GMF (Google Moja Firma). I na samym końcu postarać się usunąć negatywną opinię.
Jak działają agencje SEO?
Najlepsze efekty pozycjonowania można uzyskać przy współpracy Agencja SEO – Klient. W tym celu zazwyczaj przygotowuje się na podstawie Briefu lub ustaleń wstępnych ogólną strategię działania oraz podział prac na to, co powinieneś przygotować Ty (zdjęcia, materiały, zgody, akceptację, pomoc w dostępie do specjalistów z branży, itp.) oraz co będzie robić agencja (audyty, dobór fraz, pisanie treści, optymalizacja, etc.).
Praktyka wykazuje, że najlepiej sprawdzają się rozliczenia abonamentowe pozwalające agencji na dysponowanie budżetem, by zmaksymalizować efekty swoich działań. Po ustaleniu wstępnego planu przystępuje się do realizacji strategii SEO przy ścisłej współpracy komunikacyjnej po obu stronach.
Etapy pozycjonowania strony
Pozycjonowanie stron jest procesem ciągłym, dlatego poszczególne etapy tworzą pełny cykl.
- Wszelkie działania rozpoczyna się od audytu SEO i określenia sytuacji w momencie startu
- Dobiera się słowa kluczowe, na które należy zwrócić uwagę
- Następnie tworzony jest plan działań zależny od wniosków z audytu i celów jakie się chce osiągnąć
- Buduje się content potrzebny dla danej frazy lub założeń ogólnych
- Optymalizuje się stronę lub wybrane podstrony
- Przeprowadza się działania link-buildingowe
- Monitoruje się wyniki działań i reaguje na ewentualne zmiany algorytmów
- W zależności od efektów, proces ten się rozpoczyna od nowa lub obiera się kolejne założenia oraz frazy zgodne ze strategią SEO oraz Content Marketingową.
Należy pamiętać, że w zależności od branży, domeny lub fraz udział poszczególnych elementów i etapów może być różny.
Ile trzeba czekać na efekty pozycjonowania?
Czas potrzebny do osiągnięcia oczekiwanych rezultatów nie jest zazwyczaj możliwy do określenia. Zależy on od wielu czynników takich jak między innymi:
- konkurencyjność fraz
- działania firm konkurencyjnych
- potencjał serwisu
- struktura witryny
- czas indeksowania zmian
- zmiany algorytmów
- i wiele innych (zwyczajowo mówi się o 200 głównych czynnikach jakie Google bierze pod uwagę przy segregowaniu wyników)
Między innymi ze względu na mnogość zmiennych nie możliwe jest określenie wprost potrzebnego czasu do osiągnięcia efektów. W niektórych przypadkach efekty będą widoczne już po 2-3 miesiącach, w innych po 12-18 miesiącach. Do pozycjonowania należy podchodzić długofalowo jeśli chce się z niego mieć wymierne korzyści.
Ile kosztuje pozycjonowanie?
Przede wszystkim wydatki na pozycjonowanie należy traktować jako inwestycję w stronę i swój biznes i to długofalową inwestycję. Jeszcze kilka lat temu powszechnie funkcjonowały cenniki usług związanych z pozycjonowaniem w odniesieniu do frazy i jej wolumenu wyszukiwania. Miało to miejsce w czasie gdy za pomocą linków można było „łatwo” manipulować wynikami, obecnie jednak to nie ma zastosowania, gdyż Google zabezpieczył się przed takimi praktykami.
Realne koszty pozycjonowania zależą od wielkości strony i konkurencyjności fraz. W skład usług SEO wchodzi nie tylko praca specjalistów (zwyczajowo 100 – 200 PLN za roboczogodzinę) ale także pisanie treści (od 20 PLN / 1000 zzs) czy pozyskiwanie linków zewnętrznych i utrzymanie własnych zasobów w tym zaplecz i narzędzi. Pozycjonowanie nie jest bardzo tanią usługą, ale jej rentowność rośnie wraz z czasem i środkami w nią włożonymi o ile jest ona realizowana pod nadzorem specjalistów.
Współpraca z agencją SEO czy samodzielne pozycjonowanie?
Mając odpowiednie środki finansowe, zaplecze techniczne i wiedzę na temat SEO można pozycjonować stronę samodzielnie. Jednak zazwyczaj jest to co najmniej nieopłacalne. Żeby skutecznie wpływać na wzrost widoczności w wyszukiwarkach, trzeba być na bieżąco zarówno z trendami jak i zmianami, które wdraża Google i na nie reagować. Prowadząc jakąkolwiek działalność lepiej ten czas (wymagany na naukę podstaw, pracę nad stroną i monitoring) przeznaczyć na własnych klientów.
Podstawowe informacje dotyczące pozycjonowania można przy odrobinie czasu znaleźć w internecie. Należy jednak bardzo krytycznie podchodzić do znalezionych źródeł, gdyż wiele aspektów ulega zmianie na przestrzeni lat. Najpewniejszą metodą jest zasięgnięcie rady specjalisty lub agencji. Można skorzystać z jednorazowych konsultacji, jednak bez wystarczającej wiedzy technicznej i doświadczenia może się okazać, że to nie wystarczy by sprawnie poprawiać widoczność serwisu. W takich przypadkach lepiej zdecydować się na kompleksową obsługę i doradztwo z pomocą agencji SEO.
Mity spotykane na temat SEO
Ponieważ nikt nie zna wszystkich czynników wpływających na pozycjonowanie przez lata powstało wiele mitów na temat tego jak ono działa. Wynika to między innymi z faktu, że z biegiem czasu czynniki wpływające na pozycje ulegały zmianom na skutek aktualizacji algorytmów. Popularnymi mitami w pozycjonowaniu są między innymi:
- GWARANCJA NA OSIĄGNIĘCIE POZYCJI DANYCH FRAZ
- GWARANCJA WZROSTU SPRZEDAŻY
- IM WIĘCEJ LINKÓW TYM LEPIEJ
- TYLKO LINKI DOFOLLOW Z ANCHORAMI EXACT-MATCH MAJĄ ZNACZENIE
- DOBRA TREŚĆ BRONI SIĘ SAMA
- WYSTARCZY TYLKO SILNA DOMENA
Weryfikacja znalezionych w internecie informacji o pozycjonowaniu, jeśli nie zajmujesz się SEO na co dzień do najłatwiejszych nie należy. Dlatego najlepiej konsultować się ze swoim pozycjonerem.
Czym jest pozycjonowanie stron www?
Pozycjonowanie stron www to długofalowy, rozbudowany proces promocji serwisów w Internecie. Celem pozycjonowania jest dostosowanie strony internetowej do aktualnych wymogów wyszukiwarek internetowych, zwiększenie jej widoczności w wynikach wyszukiwania oraz pozyskania wartościowego ruchu organicznego. W zależności od strony internetowej, celów oraz przyjętej strategii, pozycjonowanie może przyjąć formę promocji wyselekcjonowanych fraz kluczowych lub tzw. long-tail SEO, czyli promocji serwisu internetowego na nieograniczoną liczbą wyrażeń. Zapytaj o skuteczne pozycjonowanie Twojej strony www.
Czy pozycjonowanie jest potrzebne?
Pozycjonowanie stron www to obecnie najbardziej efektywny sposób promocji serwisów w Internecie. Jeśli poszukujesz nowych, skutecznych sposobów na pozyskanie wartościowego ruchu oraz przyciągnięcie na stronę osób zainteresowanych produktami lub usługami, które oferujesz, rozważ skuteczne pozycjonowanie strony internetowej z agencją Pozysjonowanie.pl. Skontaktuj się z nami i otrzymaj bezpłatną wycenę usługi.
Jak długo trwa pozycjonowanie strony?
Pozycjonowanie stron internetowych to długofalowy proces, który powinien być prowadzony tak długo, jak istnieje potrzeba dotarcia i pozyskania klientów przez stronę www. Efekty działań SEO mogą utrzymywać się przez jakiś czas po zakończeniu świadczenia usługi. Jednak w związku z dynamicznym i wysoce konkurencyjnym środowiskiem internetowym, zakończenie pozycjonowania może przynieść zdecydowanie więcej strat niż korzyści.
Dlaczego pozycjonowanie strony jest ważne?
Pozycjonowanie stron internetowych to obecnie najważniejszy i najbardziej efektywny w długim okresie sposób na budowę pozycji serwisu w Internecie i stałe zwiększanie liczby potencjalnych klientów. Jeśli Twoim celem jest realna rywalizacja o klienta, pozycjonowanie powinno być jednym z najważniejszych elementów Twojej strategii marketingowej.
Pozycjonowanie stron www jest procesem, który skupia się na precyzyjnym dostosowaniu serwisu do aktualnych wymogów wyszukiwarek oraz potrzeb i oczekiwań potencjalnych klientów. Najważniejszymi elementami pozycjonowania są:
- optymalizacja techniczna serwisu internetowego
- budowa naturalnej struktury odnośników,
- content marketing.
Skuteczne pozycjonowanie stron www obejmuje w praktyce rozbudowany pakiet działań prowadzonych zarówno on-site, jak i off-site, które w długim okresie umożliwiają uzyskanie wysokiej pozycji serwisu w wynikach wyszukiwania oraz podjęcie realnej walki o klienta w wysoce konkurencyjnym środowisku internetowym.
Ile kosztuje pozycjonowanie stron www?
Kosztu pozycjonowania stron internetowych nie można zamknąć w ramach sztywnych cenników. Bogaty wachlarz działań, jakie zawiera skuteczne SEO, struktura i wielkość strony www, poziom i aktywność konkurencji, zachowania klientów, sezonowość branży i wiele innych czynników istotnie wpływających na zakres niezbędnych działań uniemożliwiają jednoznacznie określenie ceny pozycjonowania bez przeprowadzenia szczegółowych analiz. Najkorzystniejszym rozwiązaniem w kontekście ceny pozycjonowania jest indywidualna wycena usługi. Skontaktuj się z nami i zapytaj o bezpłatną wycenę pozycjonowania Twojego serwisu w Internecie.
Czy pozycjonowanie zwiększy sprzedaż online?
Pozycjonowanie stron oraz sklepów internetowych służy efektywnemu budowaniu widoczności serwisów oraz pozyskiwaniu wartościowego ruchu z organicznych wyników wyszukiwania. Nie jest to jednak działanie, które bezpośrednio przekłada się na uzyskiwany poziom sprzedaży ze strony lub sklepu www. Decyzja o zakupie uzależniona jest bowiem od wielu czynników, w dużej części niezależnych od pozycjonowania. Bez skutecznego pozycjonowania dotarcie z ofertą do nowych klientów jest jednak mało prawdopodobne, co skutecznie blokuje wzrost sprzedaży online.
Czy pozycjonowanie stron się opłaca?
Pozycjonowanie stron internetowych umożliwia zdobycie widoczności serwisu w wynikach wyszukiwania oraz pozyskanie wartościowego ruchu z wyszukiwarek. Jednostkowy koszt pozyskania użytkownika z Internetu dzięki SEO maleje wraz ze wzrostem poziomu pozyskiwanego ruchu. Co więcej, skuteczne pozycjonowanie pozwala budować zaufanie użytkowników do strony www oraz lojalność klientów.
Jak szybko zobaczę efekty pozycjonowania strony internetowej?
Pozycjonowanie stron www to długofalowy proces, na którego efektywność wpływa bardzo wiele czynników, w dużym stopniu niezależnych od samej strony internetowej czy działań SEO. W związku z tym precyzyjne określenie terminu uzyskania efektów pozycjonowania jest w praktyce niemożliwe. Opierając się jednak na naszym wieloletnim doświadczeniu, możemy szacować, że w zależności od witryny oraz branży pierwsze efekty pozycjonowania strony internetowej pojawić się powinny po 4- 6 miesięcy pracy nad promocją strony www.
Czy możliwe jest pozycjonowanie mojej strony www?
Niezależnie od branży, w której funkcjonuje Twoja strona www, jej wielkości czy dotychczasowo prowadzonych działań promocyjnych, możesz objąć ją pozycjonowaniem. Jest to najbardziej skuteczna odpowiedź na potrzeby związane z poszukiwaniem efektywnych sposobów pozyskania nowych klientów. Skontaktuj się z nami już dzisiaj i zapytaj o bezpłatną wycenę pozycjonowania Twojej strony www.











Nareszcie jakieś zwięzłe konkrety o pozycjonowaniu!